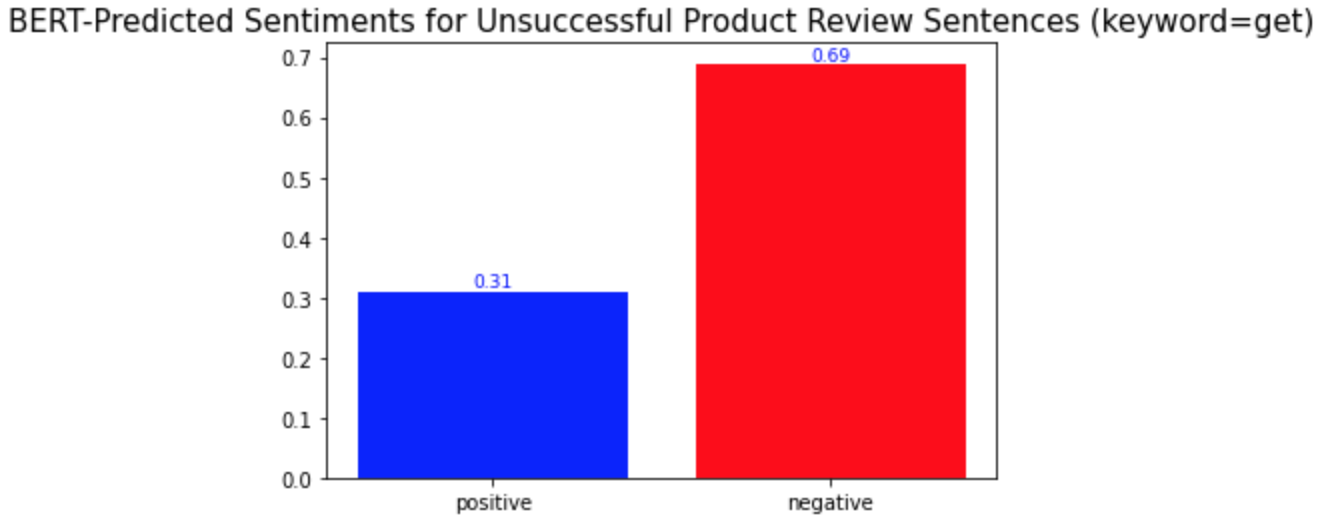
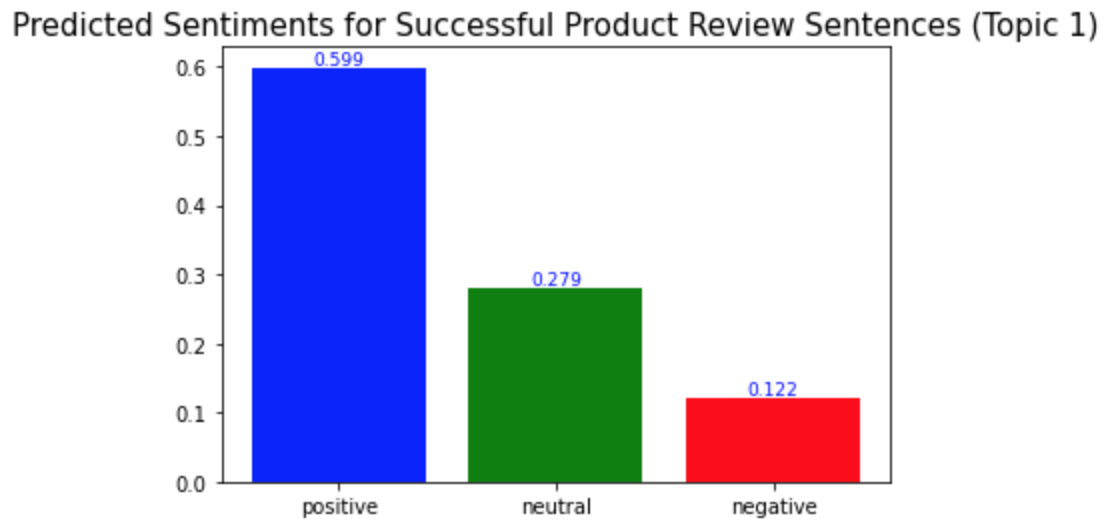
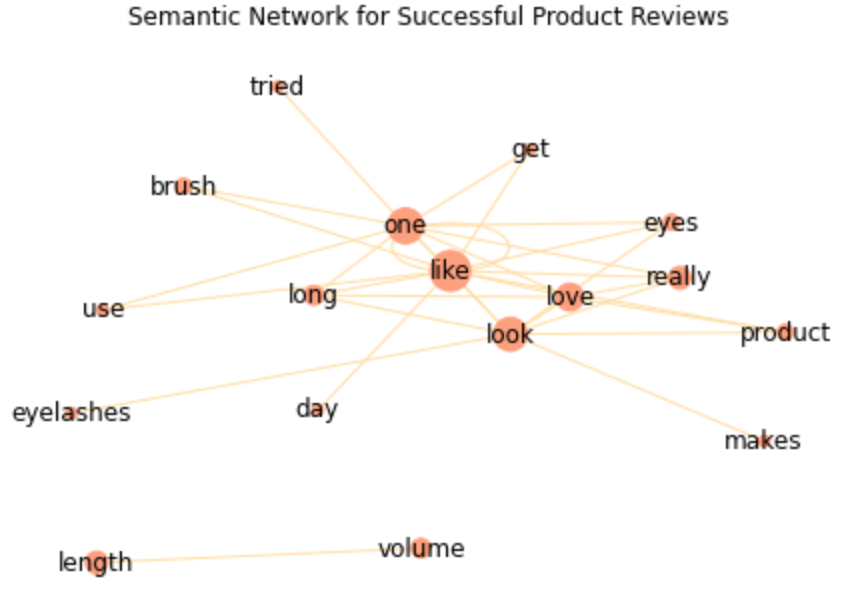
이전 포스트에서 나는 BERT를 사용하여 토픽 모델링을 진행하였다. 결과적으로, 성공적인 제품 리뷰에서는 7개의 토픽을, 성공적이지 않은 제품 리뷰에서는 3개의 토픽을 얻었다. 이번 포스트에서는 이 토픽들을 가지고 감성 분석을 진행해볼 것이다. In the previous post, I conducted the topic modeling with BERT. As a result, I got 7 topics from the successful product reviews and 3 topics from the unsuccessful product reviews. In this post, I'm going to conduct the sentiment analysis by these topics. * 아래 포..