BERT 모델을 사용한 감성 분석에서 나는 모델의 높은 정확도에 놀랐다. 그래서 이번 포스트에서는 BERT를 사용하여 토픽 모델링을 해볼 것이다. 이를 위해 Maarten Grootendorst가 개발한 BERT 기반 토픽 모델링 기법인 BERTopic을 사용할 것이다.
From the sentiment analysis with the BERT model, I was impressed with the high accuracy of the model. So, in this post, I'm going to conduct the topic modeling using BERT. For that, I'm going to use BERTopic, a BERT-based topic modeling technique developed by Maarten Grootendorst.
* BERT 파인 튜닝에 굉장히 오랜 시간이 걸리기 때문에 GPU accelerator을 사용하길 아주 아주 적극 추천한다. 이를 위해서 꼭 구글 코랩을 사용하길 바란다.
* Since the BERT model fitting step takes a while, you should use a GPU accelerator. Because of this, I highly recommend using Google Colab.
1. Install BERTopic.
pip install bertopic
2. Import necessary packages.
from bertopic import BERTopic
import pandas as pd
3. Import the datasets.
suc = pd.read_csv('suc_stopremoved.csv')
un = pd.read_csv('un_stopremoved.csv')suc_stopremoved.csv와 un_stopremoved.csv 데이터셋은 파일 이름 그대로 불용어가 제거된 리뷰 데이터를 포함한다. 이 데이터셋을 만들기 위해 사용한 코드: 아래 링크 참고
The datasets called suc_stopremoved.csv and un_stopremoved.csv literally include the review data from which stop words were already removed. To see the codes that I used to do so, please go to the following post.
https://livelyhheesun.tistory.com/20
How to Make Stop Words-Removed Datasets (13.04.2022.)
The followings are the steps and codes to make and save datasets without stop words. 1. Import necessary packages. import pandas as pd import re from nltk.corpus import stopwords 2. Download the sto..
livelyhheesun.tistory.com
4. Define the BERTopic model.
s_model = BERTopic() # for the successful product reviews
u_model = BERTopic() # for the unsuccessful product reviews
5. Get topics and probabailities.
# successful product reviews
s_review = []
for i in range(len(suc)):
s_review.append(str(suc['review'][i]))
topics, probabilities = s_model.fit_transform(s_review)# unsuccessful product reviews
u_review = []
for i in range(len(un)):
u_review.append(str(un['review'][i]))
topics, probabilities = u_model.fit_transform(u_review)
6. View the number and frequency of the topics.
# successful product reviews
s_model.get_topic_freq()
토픽 -1은 어느 토픽에도 속할 수 없는 이상치들을 모아놓은 것이기 때문에 무시하면 된다. 또, 성공적인 제품 리뷰에는 토픽이 너무 많기 때문에 빈도 수 100 이상인 토픽들만 사용하여 분석을 진행할 것이다.
Topic -1 includes outliers that couldn't belong to any topics, so I'm going to ignore it. Also, since there are too many topics, I'm going to conduct the analysis using topics only with more than 100 frequencies.
# unsuccessful product reviews
u_model.get_topic_freq()
7. See the words in each topic and name it.
s_model.get_topic(0)
s_model.get_topic(1)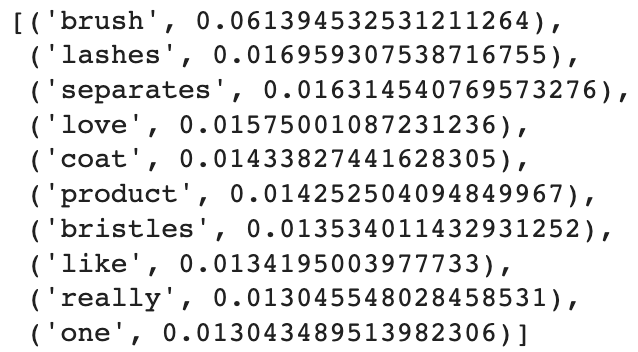
s_model.get_topic(2)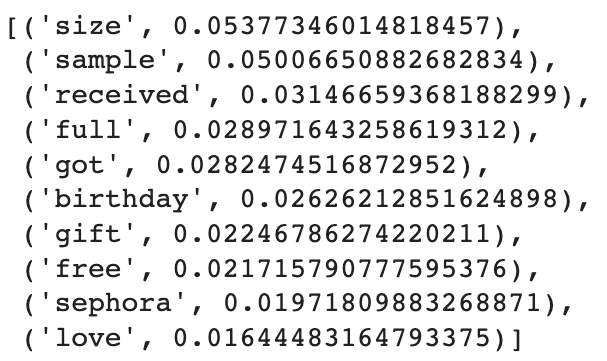
s_model.get_topic(3)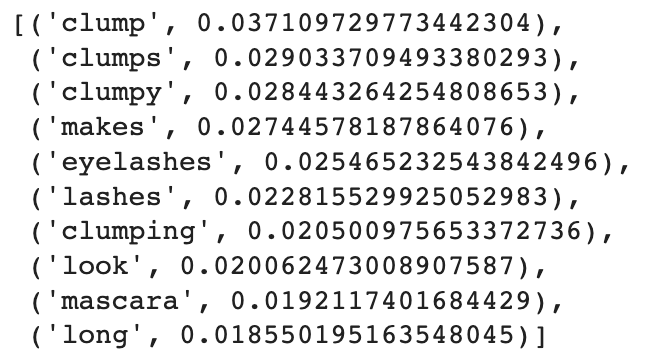
s_model.get_topic(4)
s_model.get_topic(5)
s_model.get_topic(6)
u_model.get_topic(0)
u_model.get_topic(1)
u_model.get_topic(2)
BERT 토픽 모델링을 진행해본 결과, 토픽에 이름을 붙이는 것이 훨씬 쉬웠다고 느꼈다. 이전에 LDA 토픽 모델링을 할 당시에는 각각의 토픽에 대한 적절한 이름을 찾기 위해 토픽 내 단어들을 몇 번씩이고 계속 훑어봤어야 했다. 하지만, BERTopic을 사용하니 각 토픽 내 단어들의 의미가 훨씬 일맥상통했고, 그래서 단어들을 한 번만 보고도 각 토픽에 이름을 붙일 수 있었다.
After conducting the BERT topic modeling, I especially found it much easier to name topics. During the topic modeling with LDA, I had to look through words in each topic several times to find out the appropriate name of it. However, with BERTopic, the similarity of the meaning of words in every topic was so obvious that I could name topics at once.
References
BERTopic을 사용한 Interactive Topic Modeling. (2021, January 22). 인사이트캠퍼스. http://insightcampus.co.kr:9090/insightcommunity/?mod=document&uid=12969
Grootendorst, M. (2021, December 26). Interactive Topic Modeling with BERTopic | Towards Data Science. Medium. https://towardsdatascience.com/interactive-topic-modeling-with-bertopic-1ea55e7d73d8
Interactive Topic Modeling with BERTopic
An in-depth guide to topic modeling with BERTopic
towardsdatascience.com
* Unauthorized copying and distribution of this post are not allowed.
* 해당 글에 대한 무단 배포 및 복사를 허용하지 않습니다.
'Bachelor of Business Administration @PNU > Marketing Analytics' 카테고리의 다른 글
| 토픽별 BERT 감성 분석 | BERT Sentiment Analysis by Topics (13.04.2022.) (0) | 2022.04.22 |
|---|---|
| 불용어 제거한 데이터셋 만들기 | How to Make Stop Words-Removed Datasets (13.04.2022.) (0) | 2022.04.21 |
| BERT 감성 분석 - 2 | BERT Sentiment Analysis - 2 (13.04.2022.) (0) | 2022.04.21 |
| BERT 감성 분석 - 1 | BERT Sentiment Analysis - 1 (13.04.2022.) (0) | 2022.04.20 |
| 토픽 별 감성 분석 | Sentiment Analysis for Each Topic (30.03.2022.) (0) | 2022.04.19 |