이전 포스트에서 나는 BERT 모델을 사용해 감성 예측을 하였고 고객 제품 리뷰에 1(긍정) 혹은 0(부정)의 라벨을 부여하였다. 이번 포스트에서는 감성 분석을 두 가지 방식으로 진행해보려 한다: 1) 성공한 제품 리뷰들과 성공하지 않은 제품 리뷰들에 대한 전반적인 분석, 2) 키워드 분석 (여기서 키워드란, 성공한 제품과 성공하지 않은 제품의 리뷰들을 합쳐서 단어 빈도 분석을 진행했을 때 가장 자주 언급되는 상위 10개의 단어들이라고 정의 내린다.)
In the previous post, I used the BERT model for the sentiment prediction and labeled the customer product reviews 1(positive) or 0(negative). In this post, I'm going to conduct the sentiment analysis in two ways: 1) analysis with the successful and unsuccessful product reviews in general and 2) analysis with keywords(top 10 words that were mentioned most frequently in the successful and unsuccessful product reviews as a whole).
* 이전 포스트에서 파인 튜닝을 완료한 BERT 모델을 사용할 것이다.
* I'll use the BERT model that I fine-tuned in the previous post.
1. Import necessary packages.
import pandas as pd
import matplotlib.pyplot as plt
2. Import the datasets.
suc = pd.read_csv('suc_bert.csv')
un = pd.read_csv('un_bert.csv')
3. Visualization
# successful product reviews
reaction = ['positive', 'negative']
s_pos = suc_b['label_BERT'].sum() / len(suc_b)
s_neg = 1 - s_pos
values = [s_pos, s_neg]
plt.bar(reaction, values, color=['b', 'r'])
for i, v in enumerate(reaction):
plt.text(v, values[i], round(values[i], 3), fontsize = 9, color='blue', horizontalalignment='center', verticalalignment='bottom')
plt.title('BERT-Predicted Reactions for Successful Product Reviews', fontsize=15)# unsuccessful product reviews
reaction = ['positive', 'negative']
u_pos = un_b['label_BERT'].sum() / len(un_b)
u_neg = 1 - u_pos
values = [u_pos, u_neg]
plt.bar(reaction, values, color=['b', 'r'])
for i, v in enumerate(reaction):
plt.text(v, values[i], round(values[i], 3), fontsize = 9, color='blue', horizontalalignment='center', verticalalignment='bottom')
plt.title('BERT-Predicted Reactions for Unsuccessful Product Reviews', fontsize=15)
예상한대로 성공적인 제품 리뷰에서는 긍정적인 리뷰가 더 많았고, 성공하지 않은 제품 리뷰에서는 부정적인 리뷰가 더 많았다.
As I expected, in the successful product reviews, there were more positive ones, and in the unsuccessful product reviews, there were more negative ones.
4. Sentiment analysis based on keywords
1) Word frequency analysis (without separating the product reviews into the successful and unsuccessful ones)
a) Import necessary packages.
import pandas as pd
from pandas import DataFrame
import re
from nltk.corpus import stopwords
b) Import the datasets.
suc = pd.read_csv('suc_bert.csv')
un = pd.read_csv('un_bert.csv')
c) Define the function for preprocessing.
def data_text_cleaning(data):
# 영문자 이외 문자는 공백으로 변환
only_english = re.sub('[^a-zA-Z]', ' ', data)
# 소문자 변환
no_capitals = only_english.lower().split()
# 불용어 제거
stops = set(stopwords.words('english'))
added_stops = ['mascara', 'mascaras', 'tarte', 'ilia', 'benefit', 'cosmetics', 'sephora', 'collection', 'lara', 'devgan', 'scientific', 'beauty', 'guerlain', 'clinique']
no_stops = [word for word in no_capitals if not word in stops]
no_stops = [word for word in no_stops if not word in added_stops]
return no_stops
d) Preprocess and create the lists of words from the successful and unsuccessful product reviews.
# successful product reviews
sreview_list = []
for i in range(len(suc)):
sreview = str(suc['review'][i])
suc['review'][i] = data_text_cleaning(sreview)
sreview_list += suc['review'][i]
# unsuccessful product reviews
ureview_list = []
for i in range(len(un)):
ureview = str(un['review'][i])
un['review'][i] = data_text_cleaning(ureview)
ureview_list += un['review'][i]
e) Get 10 words that were most frequently mentioned from the entire product reviews.
review_list = sreview_list + ureview_list
top_words = pd.Series(review_list).value_counts().head(10)
print("Top 10 words from product reviews")
print(top_words)
f) Create a data frame with the data and save it as a CSV file.
top_words = DataFrame(pd.Series(review_list).value_counts().head(10))
top_words.rename(columns={0:'Frequency'}, inplace=True)
top_words['Rank'] = 0
for i in range(0, 10):
top_words['Rank'][i] = i + 1
top_words = top_words.reset_index().set_index('Rank')
top_words.rename(columns={'index':'Word'}, inplace=True)
top_words.to_csv('top 10 words.csv')아래 첨부한 CSV 파일은 위 단어 빈도 분석 코드의 결과이다. 이 10개의 단어들이 이제부터 키워드별 감성 분석에 내가 사용할 키워드들이다.
The attached CSV document below is the result of the codes above. These ten words are the keywords that I'm going to use in the keyword sentiment analysis from now on.
2) Sentiment analysis
a) Import necessary packages and download Punkt Sentence Tokenizer.
import matplotlib.pyplot as plt
from nltk.tokenize import sent_tokenize
import nltk
nltk.download('punkt')
b) Import the datasets.
suc = pd.read_csv('suc_bert.csv')
un = pd.read_csv('un_bert.csv')
c) Separate every review sentence.
# successful product reviews
s_sentences = []
for i in range(len(suc['review'])):
s_sentences += sent_tokenize(str(suc['review'][i]))
# unsuccessful product reviews
u_sentences = []
for i in range(len(un['review'])):
u_sentences += sent_tokenize(str(un['review'][i]))
d) Keyword sentiment analysis
# 1) lashes
# successful product reviews
skey_sentences1 = []
for i in range(len(s_sentences)):
if ' lashes ' in s_sentences[i]:
skey_sentences1.append(s_sentences[i])
len(skey_sentences1) # 4813
sk1_labels = []
for i in range(962):
sk_list = skey_sentences1[i*5:i*5+5]
tf_batch = tokenizer(sk_list, max_length=128, padding=True, truncation=True, return_tensors='tf')
tf_outputs = model(tf_batch)
tf_predictions = tf.nn.softmax(tf_outputs[0], axis=-1)
labels = [0, 1]
label = tf.argmax(tf_predictions, axis=1)
label = label.numpy()
for j in range(len(sk_list)):
sk1_labels.append(labels[label[j]])
sk_list_962 = skey_sentences1[4810:]
tf_batch = tokenizer(sk_list_962, max_length=128, padding=True, truncation=True, return_tensors='tf')
tf_outputs = model(tf_batch)
tf_predictions = tf.nn.softmax(tf_outputs[0], axis=-1)
labels = [0, 1]
label = tf.argmax(tf_predictions, axis=1)
label = label.numpy()
for j in range(len(sk_list_962)):
sk1_labels.append(labels[label[j]])
# unsuccessful product reviews
ukey_sentences1 = []
for i in range(len(u_sentences)):
if ' lashes ' in u_sentences[i]:
ukey_sentences1.append(u_sentences[i])
len(ukey_sentences1) # 76
uk1_labels = []
for i in range(15):
uk_list = ukey_sentences1[i*5:i*5+5]
tf_batch = tokenizer(uk_list, max_length=128, padding=True, truncation=True, return_tensors='tf')
tf_outputs = model(tf_batch)
tf_predictions = tf.nn.softmax(tf_outputs[0], axis=-1)
labels = [0, 1]
label = tf.argmax(tf_predictions, axis=1)
label = label.numpy()
for j in range(len(uk_list)):
uk1_labels.append(labels[label[j]])
uk_list_15 = ukey_sentences1[75:]
tf_batch = tokenizer(uk_list_15, max_length=128, padding=True, truncation=True, return_tensors='tf')
tf_outputs = model(tf_batch)
tf_predictions = tf.nn.softmax(tf_outputs[0], axis=-1)
labels = [0, 1]
label = tf.argmax(tf_predictions, axis=1)
label = label.numpy()
for j in range(len(uk_list_15)):
uk1_labels.append(labels[label[j]])여기에서도 OOM 에러로 인해 배치 크기를 5로 줄였다. 왜 이 에러가 발생하고 어떻게 해결하는지 모른다면, 아래 링크로 연결된 포스트로 가길 바란다. 거기에서 이 에러를 어떻게 다루는지 간단하게 설명을 해놓았다.
Also here, due to the OOM errors, I reduced the batch size to 5. If you don't know why the errors occur and how to solve them, please go to the following post. There, I briefly explained how I dealt with the errors.
https://livelyhheesun.tistory.com/18
BERT Sentiment Analysis - 1 (13.04.2022.)
In the previous meeting, one of the fellow students introduced BERT. It was my first time learning about BERT, which made me more interested in it. BERT is an abbreviation of Bidirectional Encoder R..
livelyhheesun.tistory.com
e) Visualization
# successful product reviews
reaction = ['positive', 'negative']
pos = sk1_labels.count(1) / len(sk1_labels)
neg = 1 - pos
values = [pos, neg]
plt.bar(reaction, values, color=['b', 'r'])
for i, v in enumerate(reaction):
plt.text(v, values[i], round(values[i], 3), fontsize = 9, color='blue', horizontalalignment='center', verticalalignment='bottom')
plt.title('BERT-Predicted Sentiments for Successful Product Review Sentences (keyword=lashes)', fontsize=15)# unsuccessful product reviews
reaction = ['positive', 'negative']
pos = uk1_labels.count(1) / len(uk1_labels)
neg = 1 - pos
values = [pos, neg]
plt.bar(reaction, values, color=['b', 'r'])
for i, v in enumerate(reaction):
plt.text(v, values[i], round(values[i], 3), fontsize = 9, color='blue', horizontalalignment='center', verticalalignment='bottom')
plt.title('BERT-Predicted Sentiments for Unsuccessful Product Review Sentences (keyword=lashes)', fontsize=15)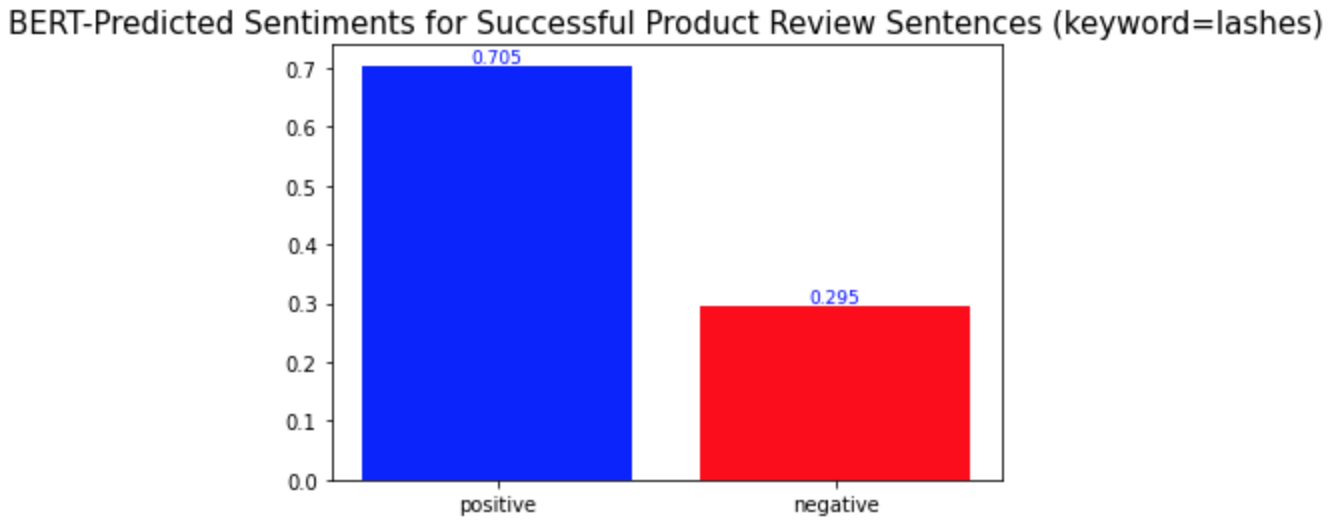
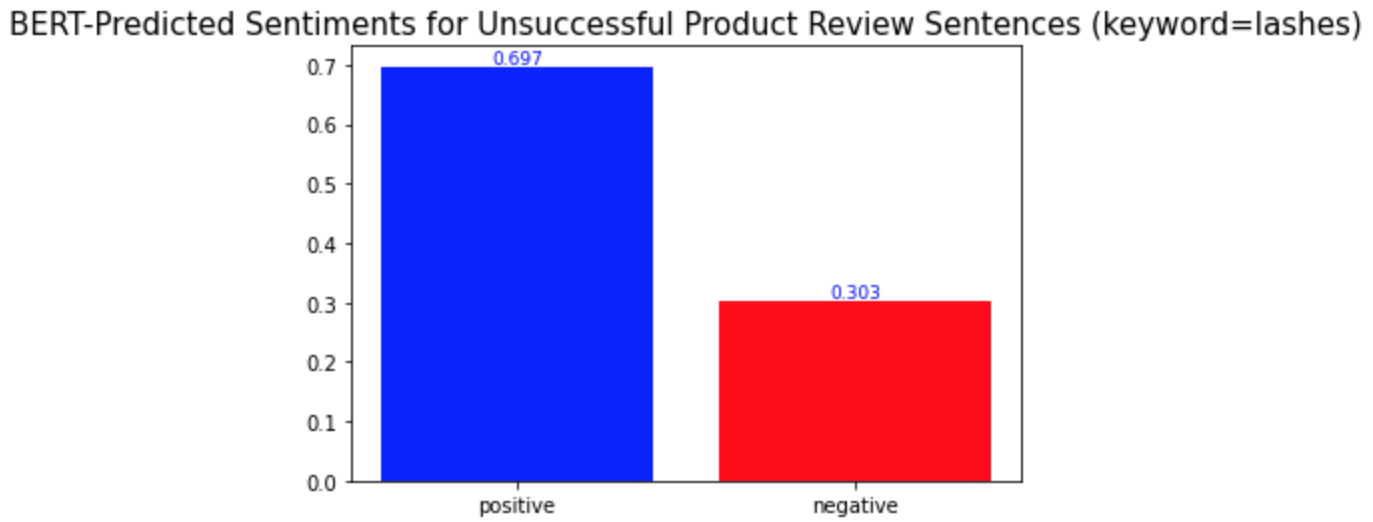
키워드 감성 분석과 모든 키워드에 대한 시각화를 반복하면 된다. 모두 완료하고 나니, 몇몇 단어들이 다른 단어들과는 다른 양상의 긍부정 감성 비율을 보인다는 것을 발견하게 되었다. 중요 키워드들은 one, product, eyes, 그리고 get이다.(다른 키워드들과 차이를 보이는 키워드들은 '중요 키워드'라고 명명하겠다.) 이 단어들의 시각화 결과는 아래와 같다.
Repeat the keyword sentiment analysis and visualization codes for every keyword. While I was doing so, I found some words that show different distributions of positive and negative sentiments from the others. They are one, product, eyes, and get. The visualization of them is as follows.
5. Visualization of the important keywords
a) one (하나의, ~것 (e.g. this one, that one))
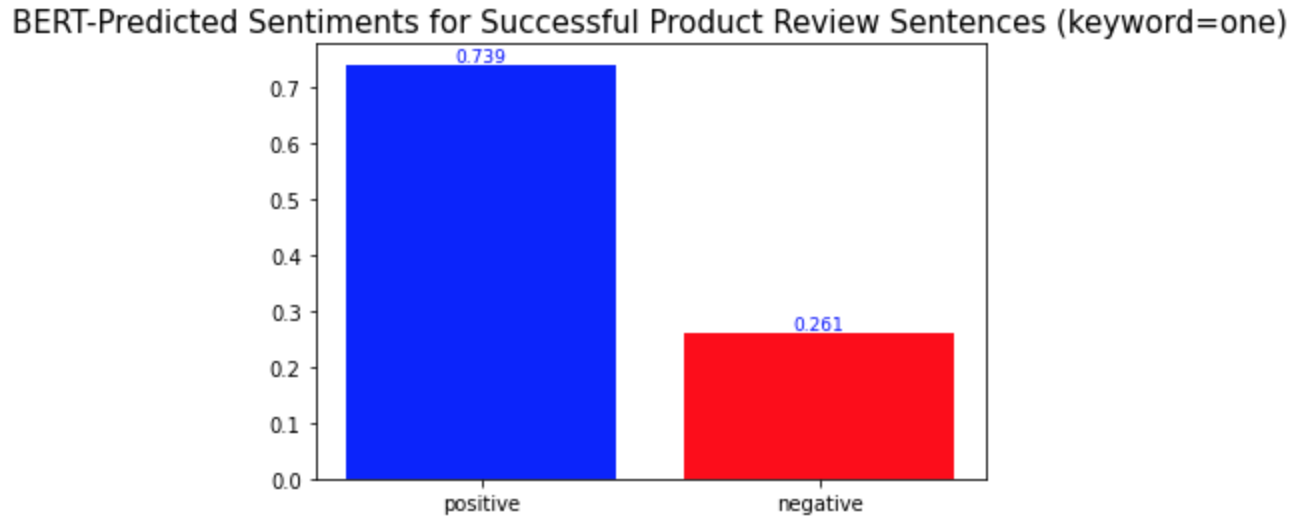
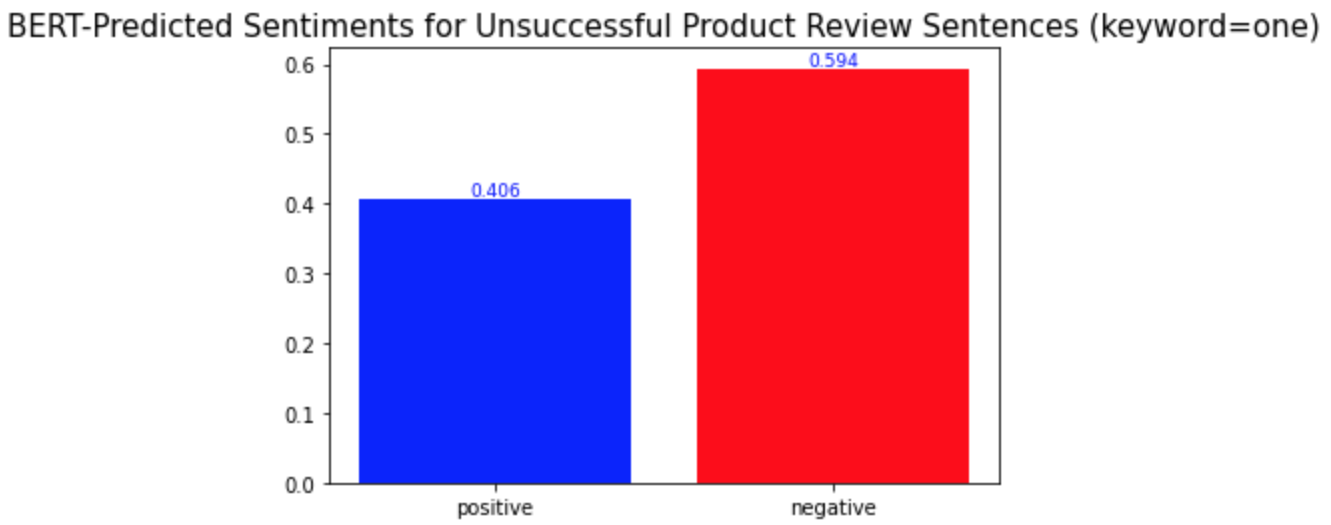
b) product
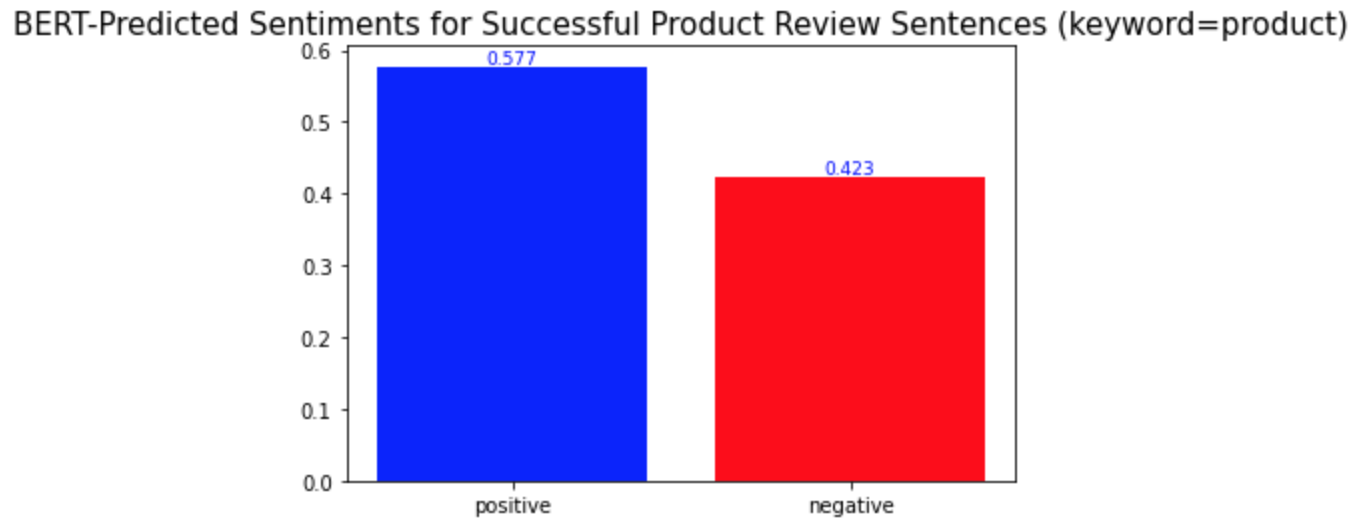
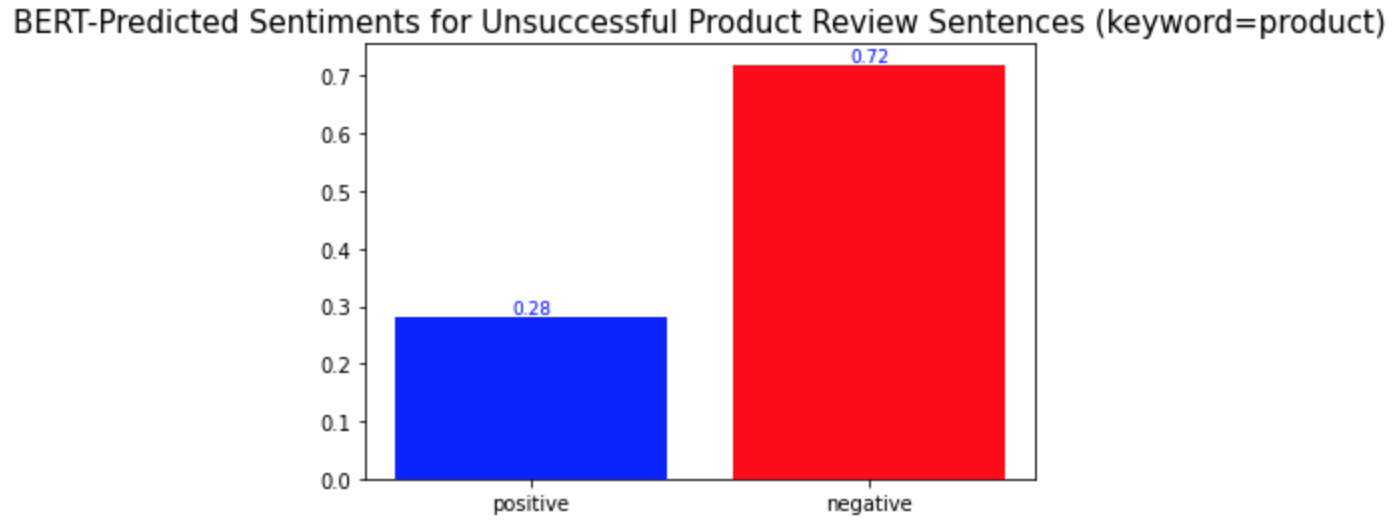
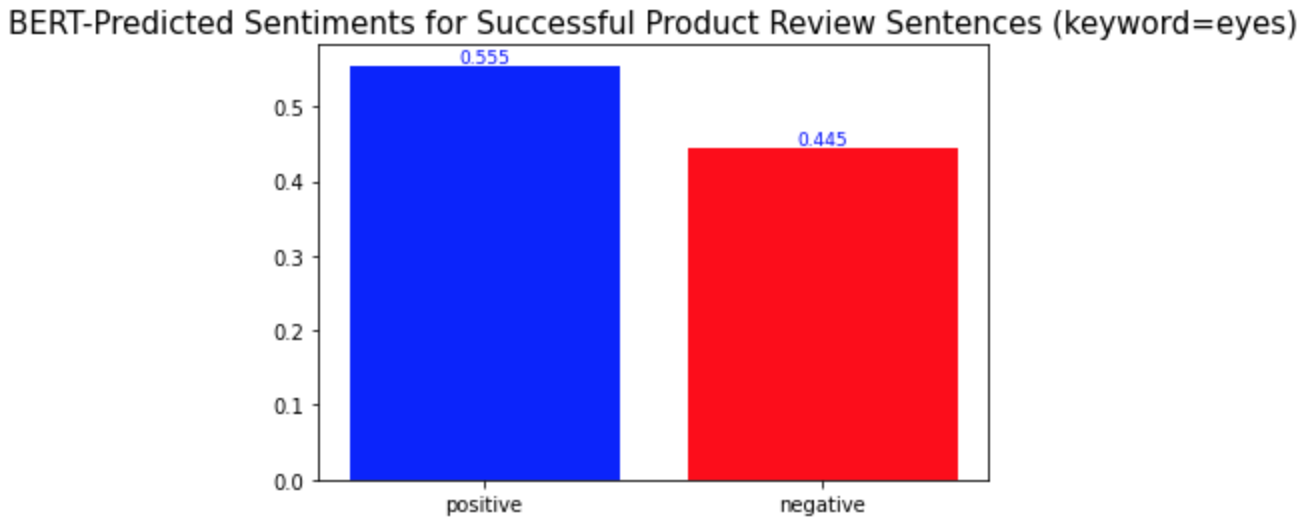
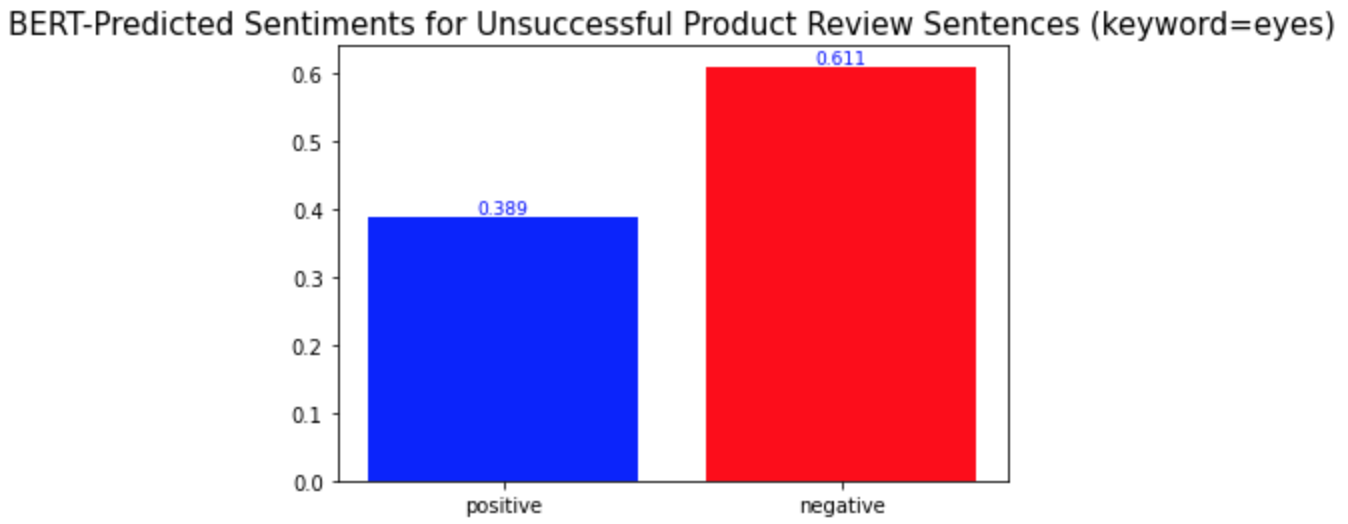
c) eyes
d) get (~을 얻다/가지다, ~을 ...하게 만들다, (+off) 제거하다/지우다)
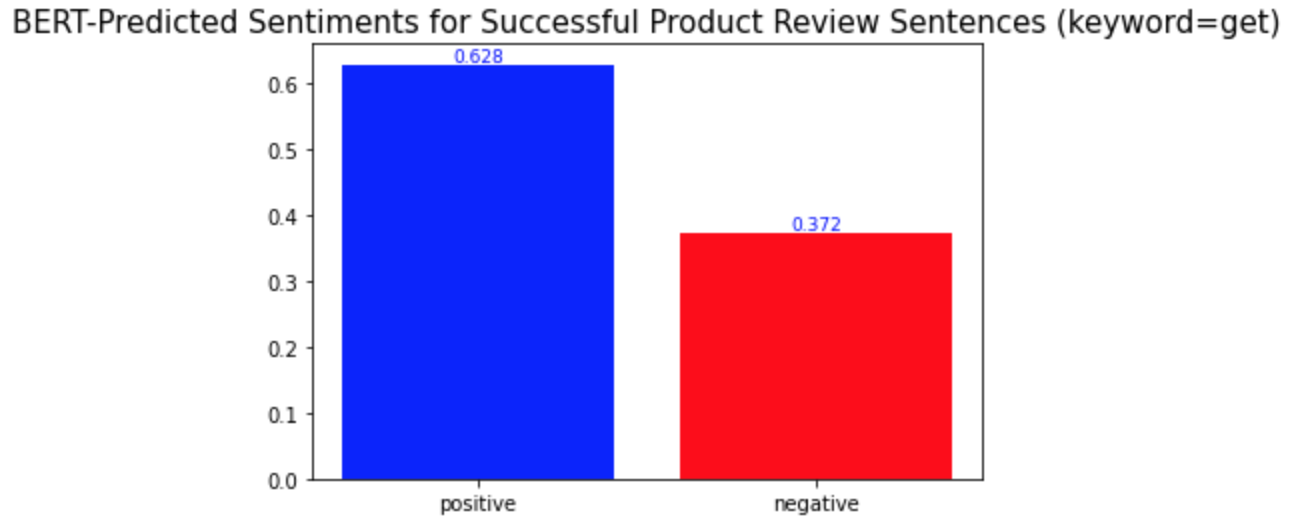
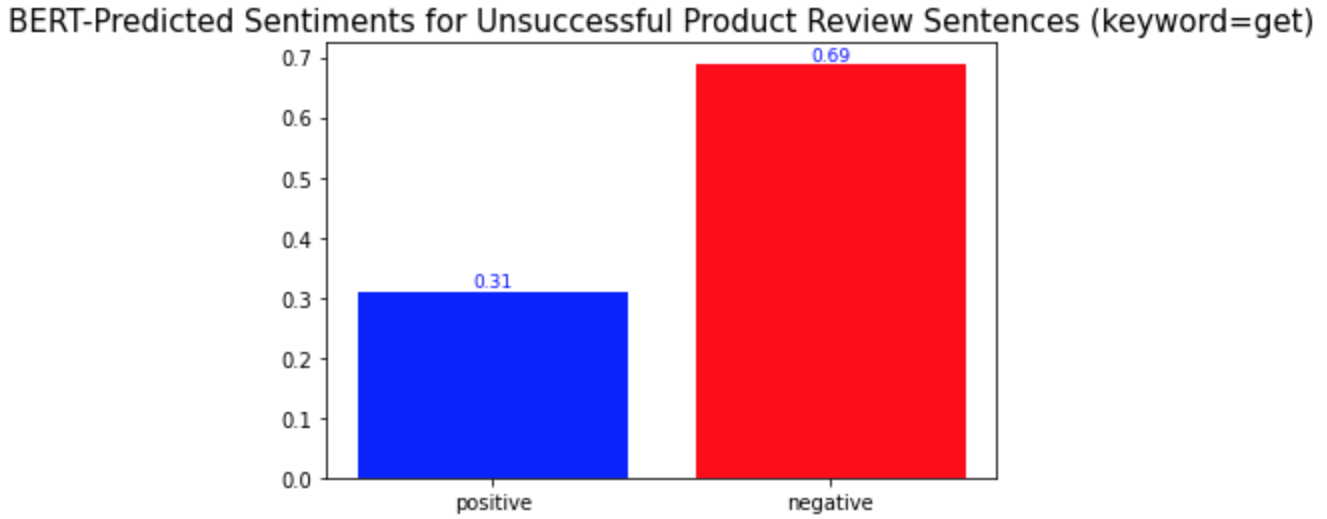
다른 키워드들과의 차이점은 이 중요 키워드들이 성공한 제품 리뷰와 성공하지 않은 제품 리뷰에서 서로 다른 감성 양상을 보인다는 것이다. 위의 'lashes'와 같은 다른 키워드들의 경우, 성공한 제품 리뷰와 성공하지 않은 제품 리뷰 모두에서 긍정적 의미로 더 많이 사용되었다. 반면, 중요 키워드들은 성공적인 제품 리뷰에서는 긍정적 의미로, 성공적이지 않은 제품 리뷰에서는 부정적 의미로 더 많이 사용되었다. 경영학적으로 적용해본다면, 이는 이 중요 키워드들이 마스카라 제품이 성공할지 아닐지를 알려주는 지표같은 역할을 할 수 있기 때문에 마스카라 제품을 판매하는 기업들은 이 키워드들에 집중해서 고객 리뷰를 검토 및 관리해야 한다는 것을 의미할 수 있다. 또, 이 중요 키워드들은 제품을 성공으로 이끌기 위해서 주의 깊게 다뤄져야 하는 부분이 될 수 있다.
What is different from the other keywords is that the important keywords show different sentimental distributions in the successful and unsuccessful product reviews. The other keywords, such as the keyword 'lashes' above, were used in similar sentimental contexts: mostly positively in the reviews of both product types. On the other hand, the important keywords were used mostly positively in the successful product reviews and mostly negatively in the other type of product reviews. In a managerial context, this can mean that they may be the words that a firm should keep track of because they may act as a sort of indicator of whether a product is successful or not. Also, they can be the keywords of aspects of a product that need to be managed carefully to make the product successful.
* Unauthorized copying and distribution of this post are not allowed.
* 해당 글에 대한 무단 배포 및 복사를 허용하지 않습니다.
'Bachelor of Business Administration @PNU > Marketing Analytics' 카테고리의 다른 글
| BERT 토픽 모델링 | BERT Topic Modeling (13.04.2022.) (0) | 2022.04.21 |
|---|---|
| 불용어 제거한 데이터셋 만들기 | How to Make Stop Words-Removed Datasets (13.04.2022.) (0) | 2022.04.21 |
| BERT 감성 분석 - 1 | BERT Sentiment Analysis - 1 (13.04.2022.) (0) | 2022.04.20 |
| 토픽 별 감성 분석 | Sentiment Analysis for Each Topic (30.03.2022.) (0) | 2022.04.19 |
| 선행 연구 - 2 | Pilot Study - 2 (16.03.2022.) (0) | 2022.04.18 |