나는 토픽에 따라 감성이 어떻게 달라지는지 알고 싶었다. 게다가 이는 경영학적 적용의 가능성도 있기에 더 해당 분석을 진행해보고 싶었다. 내가 생각한 토픽별 감성 분석의 경영학적 적용은 다음과 같다: 성공한 제품 리뷰에서의 긍정적 감성이 강한 토픽은 벤치마킹할 필요가 있는 특징으로 간주할 수 있다. 반면에 부정적 감성이 강한 토픽과 연관된 특징은 연구 개발 과정을 더 거친 후 제품에 추가되어진다면 기존의 성공한 제품에서의 단점을 보완하는 격이기 때문에 더 독특하고 더 나은 가치를 창출할 수 있다. 성공하지 않은 제품 리뷰에서의 긍정적 감성이 강한 토픽에 해당하는 부분은 심지어 성공하지 않은 제품들에서조차 긍정적 평가를 받았던 부분이기에 새로운 마스카라 제품 개발 시 기본으로 가져야 하는 부분이다. 그러나, 성공하지 않은 제품 리뷰에서의 부정적 감성이 강한 부분은 피하거나 크게 향상시킨 후 도입해야 하는 것으로 간주할 수 있다.
I wanted to know how different the sentiments are depending on each topic due to the possible future managerial implication of the result. For example, topics from successful product reviews with strong positive emotions can be considered as features to benchmark, and those with strong negative emotions can be aspects that should be added after being developed more to create more unique or better values than other currently successful brands. On the other hand, topics from unsuccessful product reviews with strong positive emotions can be regarded as necessary aspects since they are aspects that even unsuccessful products have and are evaluated positively by consumers. However, those with strong negative emotions can be thought of as features that need to be avoided or introduced after being improved a lot.
| Successful product reviews | Unsuccessful product reviews | |
| Strong positive emotions | benchmark | necessary |
| Strong negative emotions | develop more and then add | avoid / introduce after a lot of improvements |
다음은 토픽별 감성 분석 시 사용한 코드이다. (비지도 학습)
The followings are the steps and codes for the sentiment analysis for each topic. (unsupervised learning)
1. Import necessary packages.
import re
import pandas as pd
import matplotlib.pyplot as plt
from nltk.tokenize import sent_tokenize
from nltk.sentiment.vader import SentimentIntensityAnalyzer
2. Import datasets.
suc = pd.read_csv('suc.csv')
un = pd.read_csv('un.csv')
3. Create lists with topic keywords(top 10 words in each topic).
# successful product reviews
s_topic1 = [' lash ', ' love ', ' use ', ' curl ', ' make ', ' look ', ' long ', ' product ', ' go ', ' try ']
s_topic2 = [' try ', ' lash ', ' use ', ' product ', ' look ', ' good ', ' love ', ' get ', ' well ', ' buy ']
s_topic3 = [' lash ', ' look ', ' get ', ' use ', ' love ', ' really ', ' long ', ' clump ', ' make ', ' volume ']
s_topic4 = [' use ', ' well ', ' look ', ' lash ', ' eye ', ' eyelash ', ' love ', ' clump ', ' get ', ' brush ']
s_topic5 = [' lash ', ' eye ', ' look ', 'curl ', ' make ', ' long ', ' use ', ' day ', ' really ', ' good ']
# unsuccessful product reviews
u_topic1 = [' lash ', ' day ', ' use ', ' waterproof ', ' look ', ' remove ', ' curl ', ' get ', ' even ', ' hold ']
u_topic2 = [' lash ', ' remove ', ' product ', ' use ', ' really ', ' curl ', ' volume ', ' eye ', ' makeup ', ' review ']
u_topic3 = [' lash ', ' use ', ' make ', ' look ', ' get ', ' try ', ' eye ', ' product ', ' dry ', ' love ']
u_topic4 = [' lash ', ' use ', ' good ', ' take ', ' get ', ' eye ', ' go ', ' curl ', ' product ', ' give ']
4. Separate each sentence from the product reviews.
# successful product reviews
s_sentences = []
for i in range(len(suc['review'])):
s_sentences += sent_tokenize(str(suc['review'][i]))
# unsuccessful product reviews
u_sentences = []
for i in range(len(un['review'])):
u_sentences += sent_tokenize(str(un['review'][i]))
5. Create lists with sentences that contain keywords of each topic.
# successful product reviews
skey_sentences1 = []
skey_sentences2 = []
skey_sentences3 = []
skey_sentences4 = []
skey_sentences5 = []
for i in range(len(s_sentences)):
for j in range(len(s_topic1)):
if s_topic1[j] in s_sentences[i]:
skey_sentences1.append(s_sentences[i])
for i in range(len(s_sentences)):
for j in range(len(s_topic2)):
if s_topic2[j] in s_sentences[i]:
skey_sentences2.append(s_sentences[i])
for i in range(len(s_sentences)):
for j in range(len(s_topic3)):
if s_topic3[j] in s_sentences[i]:
skey_sentences3.append(s_sentences[i])
for i in range(len(s_sentences)):
for j in range(len(s_topic4)):
if s_topic4[j] in s_sentences[i]:
skey_sentences4.append(s_sentences[i])
for i in range(len(s_sentences)):
for j in range(len(s_topic5)):
if s_topic5[j] in s_sentences[i]:
skey_sentences5.append(s_sentences[i])
skey_sentences1 = list(set(skey_sentences1))
skey_sentences2 = list(set(skey_sentences2))
skey_sentences3 = list(set(skey_sentences3))
skey_sentences4 = list(set(skey_sentences4))
skey_sentences5 = list(set(skey_sentences5))
# unsuccessful product reviews
ukey_sentences1 = []
ukey_sentences2 = []
ukey_sentences3 = []
ukey_sentences4 = []
for i in range(len(u_sentences)):
for j in range(len(u_topic1)):
if u_topic1[j] in u_sentences[i]:
ukey_sentences1.append(u_sentences[i])
for i in range(len(u_sentences)):
for j in range(len(u_topic2)):
if u_topic2[j] in u_sentences[i]:
ukey_sentences2.append(u_sentences[i])
for i in range(len(u_sentences)):
for j in range(len(u_topic3)):
if u_topic3[j] in u_sentences[i]:
ukey_sentences3.append(u_sentences[i])
for i in range(len(u_sentences)):
for j in range(len(u_topic4)):
if u_topic4[j] in u_sentences[i]:
ukey_sentences4.append(u_sentences[i])
ukey_sentences1 = list(set(ukey_sentences1))
ukey_sentences2 = list(set(ukey_sentences2))
ukey_sentences3 = list(set(ukey_sentences3))
ukey_sentences4 = list(set(ukey_sentences4))
6. Define the function for preprocessing.
def data_text_cleaning(data):
# 영문자 이외 문자는 공백으로 변환
only_english = re.sub('[^a-zA-Z]', ' ', data)
# 소문자 변환
no_capitals = only_english.lower()
return no_capitals
7. Preprocessing
# successful product reviews
for i in range(len(skey_sentences1)):
skey_sentences1[i] = data_text_cleaning(str(skey_sentences1[i]))
for i in range(len(skey_sentences2)):
skey_sentences2[i] = data_text_cleaning(str(skey_sentences2[i]))
for i in range(len(skey_sentences3)):
skey_sentences3[i] = data_text_cleaning(str(skey_sentences3[i]))
for i in range(len(skey_sentences4)):
skey_sentences4[i] = data_text_cleaning(str(skey_sentences4[i]))
for i in range(len(skey_sentences5)):
skey_sentences5[i] = data_text_cleaning(str(skey_sentences5[i]))
# unsuccessful product reviews
for i in range(len(ukey_sentences1)):
ukey_sentences1[i] = data_text_cleaning(str(ukey_sentences1[i]))
for i in range(len(ukey_sentences2)):
ukey_sentences2[i] = data_text_cleaning(str(ukey_sentences2[i]))
for i in range(len(ukey_sentences3)):
ukey_sentences3[i] = data_text_cleaning(str(ukey_sentences3[i]))
for i in range(len(ukey_sentences4)):
ukey_sentences4[i] = data_text_cleaning(str(ukey_sentences4[i]))
8. Define the function for sentiment labeling using SentimentIntensityAnalyzer().
# 임계치설정(보통 0.1)을 통해 compound(총 감성지수)가 임계치값보다 높으면 긍정(1), 낮으면 부정(-1)으로 분석
def get_sentiment(review):
analyzer = SentimentIntensityAnalyzer()
scores = analyzer.polarity_scores(review)
compound_score = scores['compound']
final_sentiment = 1 if compound_score > 0.1 else 0 if compound_score <= 0.1 and compound_score >= -0.1 else -1
# 1 긍정, 0 중립, -1 부정
return final_sentiment
9. Sentiment labeling (Create lists of sentiment labels.)
# successful product reviews
skey_labels1 = []
skey_labels2 = []
skey_labels3 = []
skey_labels4 = []
skey_labels5 = []
# 임계값은 0.1로 설정
for i in range(len(skey_sentences1)):
label1 = get_sentiment(str(skey_sentences1[i]))
skey_labels1.append(label1)
for i in range(len(skey_sentences2)):
label2 = get_sentiment(str(skey_sentences2[i]))
skey_labels2.append(label2)
for i in range(len(skey_sentences3)):
label3 = get_sentiment(str(skey_sentences3[i]))
skey_labels3.append(label3)
for i in range(len(skey_sentences4)):
label4 = get_sentiment(str(skey_sentences4[i]))
skey_labels4.append(label4)
for i in range(len(skey_sentences5)):
label5 = get_sentiment(str(skey_sentences5[i]))
skey_labels5.append(label5)
# unsuccessful product reviews
ukey_labels1 = []
ukey_labels2 = []
ukey_labels3 = []
ukey_labels4 = []
# 임계값은 0.1로 설정
for i in range(len(ukey_sentences1)):
label1 = get_sentiment(str(ukey_sentences1[i]))
ukey_labels1.append(label1)
for i in range(len(ukey_sentences2)):
label2 = get_sentiment(str(ukey_sentences2[i]))
ukey_labels2.append(label2)
for i in range(len(ukey_sentences3)):
label3 = get_sentiment(str(ukey_sentences3[i]))
ukey_labels3.append(label3)
for i in range(len(ukey_sentences4)):
label4 = get_sentiment(str(ukey_sentences4[i]))
ukey_labels4.append(label4)
10. Visualization (Draw bar charts showing ratio of review sentences with positive, neutral, and negative sentiments.)
# successful - topic 1
reaction = ['positive', 'neutral', 'negative']
s_pos1 = list(skey_labels1).count(1) / len(skey_labels1)
s_neu1 = list(skey_labels1).count(0) / len(skey_labels1)
s_neg1 = 1 - s_pos1 - s_neu1
values = [s_pos1, s_neu1, s_neg1]
plt.bar(reaction, values, color=['b', 'g', 'r'])
for i, v in enumerate(reaction):
plt.text(v, values[i], round(values[i], 3), fontsize = 9, color='blue', horizontalalignment='center', verticalalignment='bottom')
plt.title('Predicted Sentiments for Successful Product Review Sentences (Topic 1)', fontsize=15)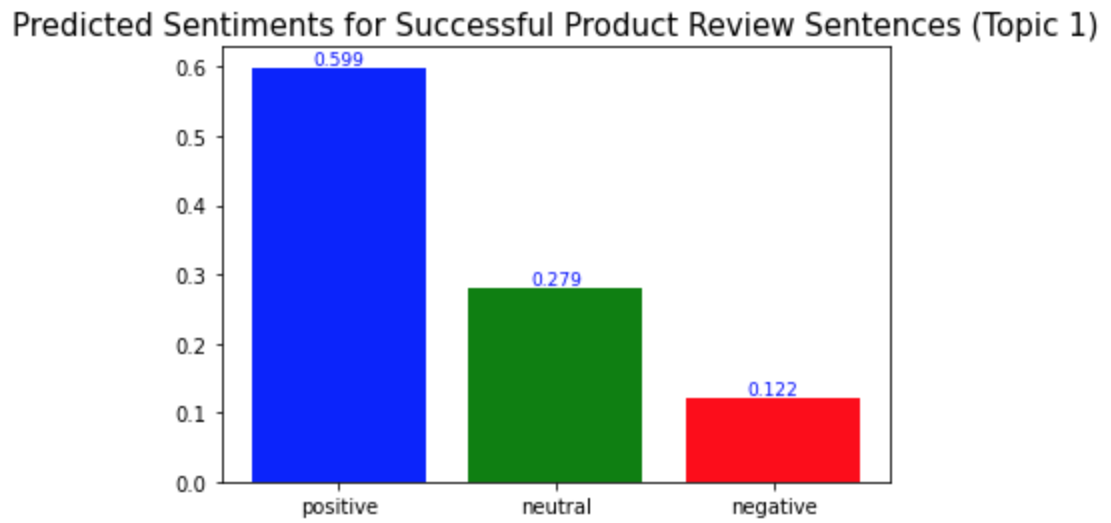
# successful - topic 2
reaction = ['positive', 'neutral', 'negative']
s_pos2 = list(skey_labels2).count(1) / len(skey_labels2)
s_neu2 = list(skey_labels2).count(0) / len(skey_labels2)
s_neg2 = 1 - s_pos2 - s_neu2
values = [s_pos2, s_neu2, s_neg2]
plt.bar(reaction, values, color=['b', 'g', 'r'])
for i, v in enumerate(reaction):
plt.text(v, values[i], round(values[i], 3), fontsize = 9, color='blue', horizontalalignment='center', verticalalignment='bottom')
plt.title('Predicted Sentiments for Successful Product Review Sentences (Topic 2)', fontsize=15)
# successful - topic 3
reaction = ['positive', 'neutral', 'negative']
s_pos3 = list(skey_labels3).count(1) / len(skey_labels3)
s_neu3 = list(skey_labels3).count(0) / len(skey_labels3)
s_neg3 = 1 - s_pos3 - s_neu3
values = [s_pos3, s_neu3, s_neg3]
plt.bar(reaction, values, color=['b', 'g', 'r'])
for i, v in enumerate(reaction):
plt.text(v, values[i], round(values[i], 3), fontsize = 9, color='blue', horizontalalignment='center', verticalalignment='bottom')
plt.title('Predicted Sentiments for Successful Product Review Sentences (Topic 3)', fontsize=15)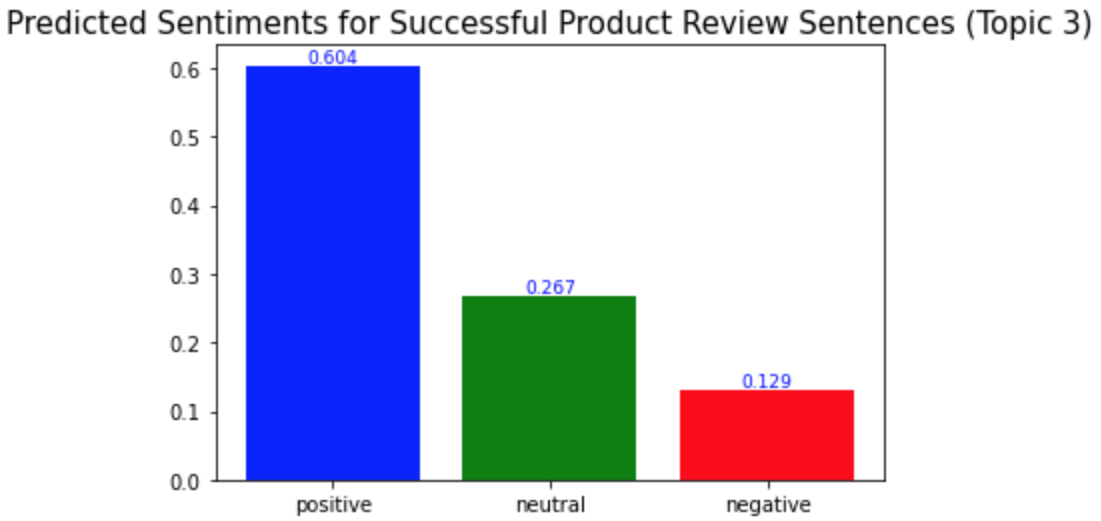
# successful - topic 4
reaction = ['positive', 'neutral', 'negative']
s_pos4 = list(skey_labels4).count(1) / len(skey_labels4)
s_neu4 = list(skey_labels4).count(0) / len(skey_labels4)
s_neg4 = 1 - s_pos4 - s_neu4
values = [s_pos4, s_neu4, s_neg4]
plt.bar(reaction, values, color=['b', 'g', 'r'])
for i, v in enumerate(reaction):
plt.text(v, values[i], round(values[i], 3), fontsize = 9, color='blue', horizontalalignment='center', verticalalignment='bottom')
plt.title('Predicted Sentiments for Successful Product Review Sentences (Topic 4)', fontsize=15)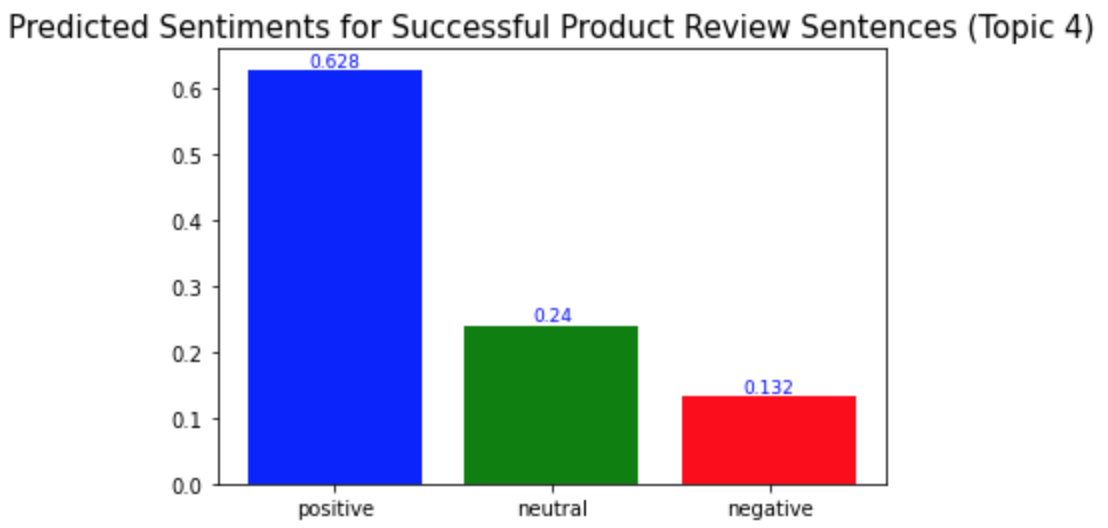
# successful - topic 5
reaction = ['positive', 'neutral', 'negative']
s_pos5 = list(skey_labels5).count(1) / len(skey_labels5)
s_neu5 = list(skey_labels5).count(0) / len(skey_labels5)
s_neg5 = 1 - s_pos5 - s_neu5
values = [s_pos5, s_neu5, s_neg5]
plt.bar(reaction, values, color=['b', 'g', 'r'])
for i, v in enumerate(reaction):
plt.text(v, values[i], round(values[i], 3), fontsize = 9, color='blue', horizontalalignment='center', verticalalignment='bottom')
plt.title('Predicted Sentiments for Successful Product Review Sentences (Topic 5)', fontsize=15)
# unsuccessful - topic 1
reaction = ['positive', 'neutral', 'negative']
u_pos1 = list(ukey_labels1).count(1) / len(ukey_labels1)
u_neu1 = list(ukey_labels1).count(0) / len(ukey_labels1)
u_neg1 = 1 - u_pos1 - u_neu1
values = [u_pos1, u_neu1, u_neg1]
plt.bar(reaction, values, color=['b', 'g', 'r'])
for i, v in enumerate(reaction):
plt.text(v, values[i], round(values[i], 3), fontsize = 9, color='blue', horizontalalignment='center', verticalalignment='bottom')
plt.title('Predicted Sentiments for Unsuccessful Product Review Sentences (Topic 1)', fontsize=15)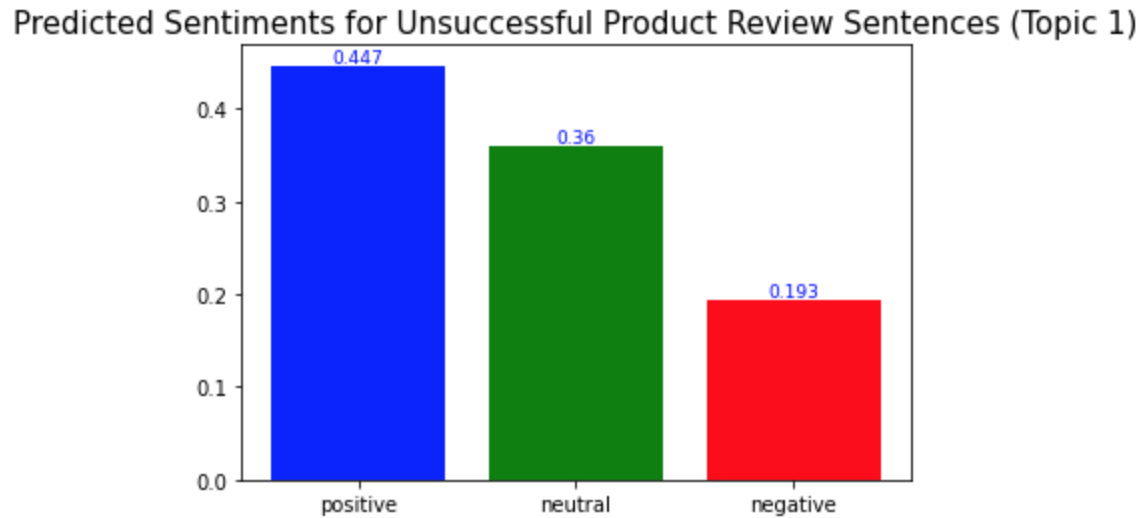
# unsuccessful - topic 2
reaction = ['positive', 'neutral', 'negative']
u_pos2 = list(ukey_labels2).count(1) / len(ukey_labels2)
u_neu2 = list(ukey_labels2).count(0) / len(ukey_labels2)
u_neg2 = 1 - u_pos2 - u_neu2
values = [u_pos2, u_neu2, u_neg2]
plt.bar(reaction, values, color=['b', 'g', 'r'])
for i, v in enumerate(reaction):
plt.text(v, values[i], round(values[i], 3), fontsize = 9, color='blue', horizontalalignment='center', verticalalignment='bottom')
plt.title('Predicted Sentiments for Unsuccessful Product Review Sentences (Topic 2)', fontsize=15)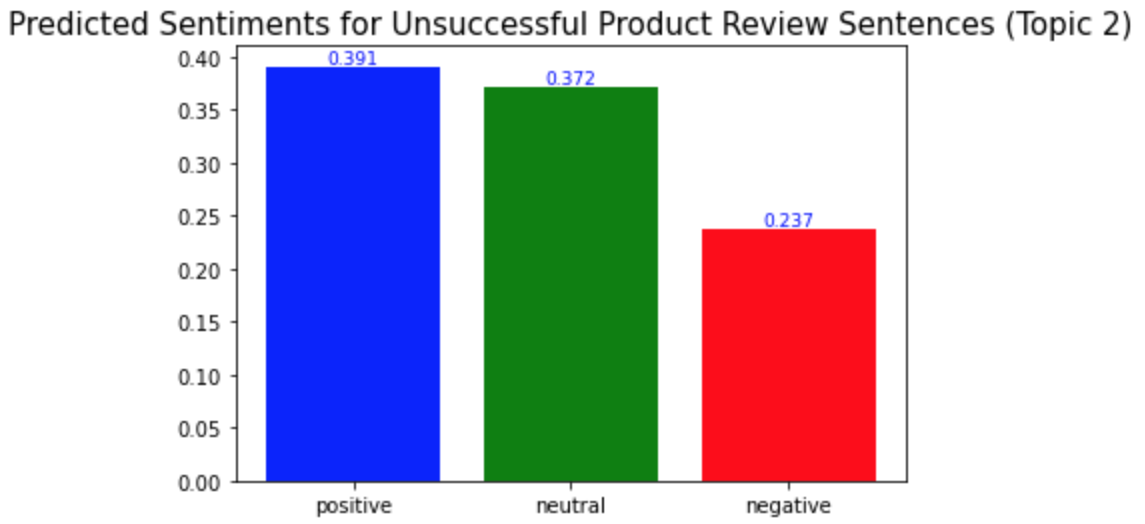
# unsuccessful - topic 3
reaction = ['positive', 'neutral', 'negative']
u_pos3 = list(ukey_labels3).count(1) / len(ukey_labels3)
u_neu3 = list(ukey_labels3).count(0) / len(ukey_labels3)
u_neg3 = 1 - u_pos3 - u_neu3
values = [u_pos3, u_neu3, u_neg3]
plt.bar(reaction, values, color=['b', 'g', 'r'])
for i, v in enumerate(reaction):
plt.text(v, values[i], round(values[i], 3), fontsize = 9, color='blue', horizontalalignment='center', verticalalignment='bottom')
plt.title('Predicted Sentiments for Unsuccessful Product Review Sentences (Topic 3)', fontsize=15)
# unsuccessful - topic 4
reaction = ['positive', 'neutral', 'negative']
u_pos4 = list(ukey_labels4).count(1) / len(ukey_labels4)
u_neu4 = list(ukey_labels4).count(0) / len(ukey_labels4)
u_neg4 = 1 - u_pos4 - u_neu4
values = [u_pos4, u_neu4, u_neg4]
plt.bar(reaction, values, color=['b', 'g', 'r'])
for i, v in enumerate(reaction):
plt.text(v, values[i], round(values[i], 3), fontsize = 9, color='blue', horizontalalignment='center', verticalalignment='bottom')
plt.title('Predicted Sentiments for Unsuccessful Product Review Sentences (Topic 4)', fontsize=15)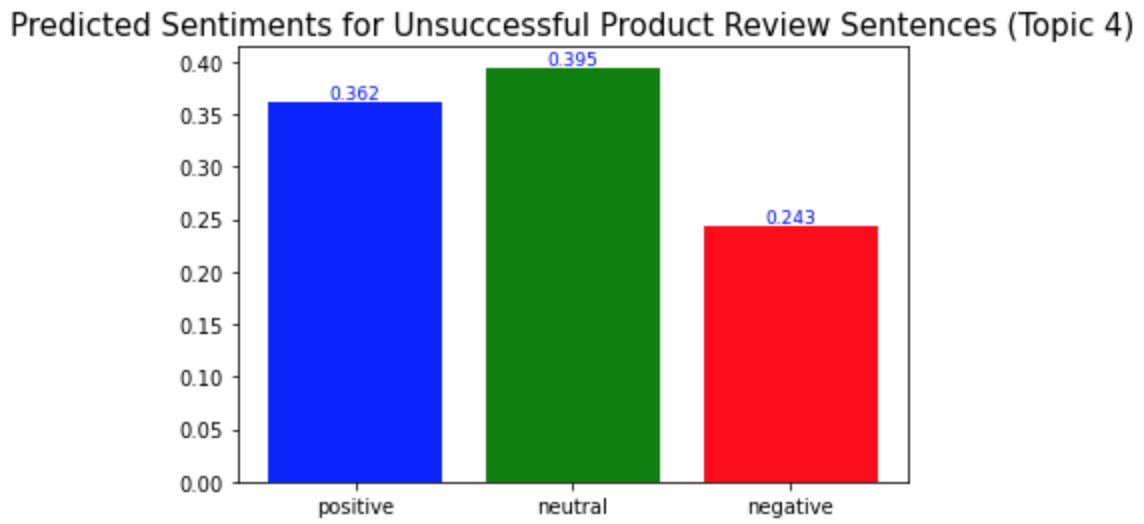
예상했던 바와 같이, 성공한 제품 리뷰의 각 토픽에서의 긍정적 문장의 비율이 성공하지 않은 제품 리뷰의 경우에서보다 더 높았다. 성공한 제품 리뷰에서는 모든 토픽에서 긍정적 문장의 비율이 0.5보다 높은 반면, 성공하지 않은 제품 리뷰에서는 모두 0.5보다 낮았다.
또다른 흥미로운 점은 감성 중립의 비율이 성공하지 않은 제품의 토픽 4(소비자들이 해당 제품을 다른 사람들에게 추천할 의향)에서만 가장 높았다는 것이다. 이는 제품의 질이 나빠질 수록 소비자들은 다른 사람들에게 그 제품에 대해 더 부정적으로 말하고, 심지어는 제품에 대한 그들의 실제 사용 경험보다 더 부정적으로 전달하는 경향이 있다는 것을 보여준다.
As I expected, the ratio of the positive sentences in the successful product reviews for each topic is higher than in the unsuccessful product reviews. In the successful product reviews, ratios of the positive sentences were more than 0.5 for all topics, but in the unsuccessful product reviews, they were all less than 0.5.
Another interesting point is that the ratio of neutrality is the highest only for topic 4 of the unsuccessful product reviews(whether consumers are willing to recommend the products to others). This shows consumers tend to talk about the products to others less positively as the product quality becomes worse, and they are likely to do so more negatively than their actual experience using the products.
* Unauthorized copying and distribution of this post are not allowed.
* 해당 글에 대한 무단 배포 및 복사를 허용하지 않습니다.
'Bachelor of Business Administration @PNU > Marketing Analytics' 카테고리의 다른 글
| BERT 감성 분석 - 2 | BERT Sentiment Analysis - 2 (13.04.2022.) (0) | 2022.04.21 |
|---|---|
| BERT 감성 분석 - 1 | BERT Sentiment Analysis - 1 (13.04.2022.) (0) | 2022.04.20 |
| 선행 연구 - 2 | Pilot Study - 2 (16.03.2022.) (0) | 2022.04.18 |
| 감성 분석 - 지도 학습 | Sentiment Analysis - Supervised Learning (16.03.2022.) (0) | 2022.04.17 |
| 구 빈도 분석 | Phrase Frequency Analysis (16.03.2022.) (0) | 2022.04.17 |